Chapter 2
Open Data and Interoperability
We should work toward a universal linked information system, in which generality and portability are more important than fancy graphics techniques and complex extra facilities
― Tim Berners-Lee (1989).
A datum, the singular form of the word data in Latin, can be translated as “a given”. When someone or something makes for example the observation that a certain train will start from the Schaerbeek station, and by recording this observation in this text, we have created a datum. In English, as well as in this PhD thesis, the word data is also often used as a singular word to refer to the abstract concept of a pile of recorded observations. When we have many things that are given, we talk about a dataset, or simply, data.
Data need a container to be stored in or transmitted with. We can store different observations in a written document, which in turn can be published as a book or can be shared online in a Web format. Data can also be stored within a database, to then be shared with others through e.g., data dumps or query services.
A data format
In order to store or transit data in a document, we need to agree on a serialization first. A simple example of such a serialization is Comma-Separated Values (csv) [1], in which the elements are separated by commas. Each line in the file contains a record and each record has a value for each column. An illustration of how a train leaving from Schaerbeek station would look like in this tabular format, is given in Figure 1.
"id","starts from" "Train P8008","Schaerbeek Station"
This is not the only way in which this data can be serialized into csv. We can imagine different headings are used, different ways to identify “Train P8008”, or even “starts from” and “Train P8008” to switch places. Each serialization only specifies a certain syntax, which tells how data elements are separated from each other. It is up to specifications on a higher abstraction layer to define how these different elements will relate to each other, based on the building blocks provided by the serialization format. The same holds true for other serializations, such as the hierarchical Javascript Object Notation (json) or Extensible Markup Language (xml) formats.
As people decide how datasets are shaped, human language is used to express facts within these serializations. Noam Chomsky, who laid the foundations of generative grammar, built models to study language as if it were a mathematical problem. In Chomskian generative grammar, the smallest building block to express a fact one can think of, is a triple. Such a triple contains a subject (such as “Train P8008”), a predicate (such as “starts from”), and an object (such as “Schaerbeek Station”). Within a triple, a subject has a certain relation to an object, and this relation is described by the predicate. In Figure 2, we illustrate how our csv example in Figure 1 would look like in a triple structure.
- Train P8008
- starts from
- Schaerbeek Station
This triple structure – rather than a tabular or hierarchical data model – helps studying data in its most essential form. It allows to extent the theory we build for one datum or triple, to more data. By re-using the same elements in triples, we are able to link and weave a graph of connected statements. json, csv, and xml are at the time of writing popular formats on the Web, that can be intepreted by any modern programming language today. No knowledge is required about these serializations in the remainder of this book. Different dedicated serializations for triples exist, such as Turtle [2] and N-Triples [3], yet also specifications exist to encode triples within serializations like json, csv, or xml.
Documenting meaning
Let us perform a thought experiment and imagine three triples published by three different authorities. One machine publishes the triple in Figure 2, while two other publish the triples illustrated in Figures 3 and 4 – the serialization used can be any – representing the facts that the train P8008 starts from Schaerbeek Station, Schaerbeek Station is located in Schaerbeek City, and the Belgian singer Jacques Brel was born this city.
- Schaerbeek Station
- located in
- Schaerbeek City
When a user agent visits these three machines, it can now answer more questions than each of the machines would be able to do on their own, such as: “What trains leave in the city in which Jacques Brel was born?”. A problem occurs however. How does this user agent know whether “Schaerbeek City” and “Schaerbeek” are the same entity?
- Jacques Brel
- born in
- Schaerbeek
Instead of using words to identify things, numeric identifiers are commonly used. This way, every organization can have their context in which entities are described and discussed. E.g., the station of Schaerbeek could be given then identifier 132, while the city of Schaerbeek could be given the identifier 121. Yet for an outsider, it becomes unclear what the meaning is of 121 and 132, as it is unclear where its semantics are documented, if documented at all.
Resources can be anything, including documents, people, physical objects, and abstract concepts [4]. Within the Resource Description Framework (rdf), they can be identified using a Uniform Resource Identifier (uri), or represented by a literal value (such as a date or a string of characters).Linked Data solves this problem by using Web identifiers, or http Uniform Resource Identifiers (uris) [5]. It is a method to distribute and scale semantics over large organizations such as the Web. When looking up this identifier – by using the http protocol or using a Web browser – a definition must be returned, including links towards potential other interesting resources. The triple format to be used in combination with uris is standardized within the rdf [4]. In Figure 5, we exemplified how these three triples would look like in rdf.
<http://phd.pietercolpaert.be/trains#P8008> <http://phd.pietercolpaert.be/terms#startsFrom> <http://irail.be/stations/NMBS/008811007> . <http://irail.be/stations/NMBS/008811007> <http://dbpedia.org/ontology/location> <http://dbpedia.org/resource/Schaerbeek> . <http://www.wikidata.org/entity/Q1666> <http://www.wikidata.org/entity/P19> <http://dbpedia.org/resource/Schaerbeek> .
One can use Linked Open Vocabularies to discover reusable uris [6]. The uris used for these triples already existed in other data sources, and we thus favoured using the same identifiers. It is up to a data publisher to make a choice on which data sources can provide the identifiers for a certain of entities. In this example, we found WikiData to be a good source to define the city of Schaerbeek and to define Jacques Brel. We however prefer iRail as a source for the stations in Belgium. As we currently did not find any existing identifiers for the train route P8008, we created our own local identifier, and used the domain name of this dissertation as a base for extending the knowledge on the Web.
Intellectual Property Rights and Open Data
As Intellectual Property Rights (ipr) legislation diverges across the world, we only checked the correctness of this chapter with European copyright legislation [7] in mind. When a document is published on the Web, all rights are reserved by default until 70 years after the death of the last author. When these documents are reused, modified and/or shared, the conscent of the copyright holder is needed. This conscent can be given through a written statement, but can also be given to everyone at once through a public license. In order to mark your own work for reuse, licenses, such as the Creative Commons licenses, exist, that can be reused without having to invent the same legal texts over and over again.
Copyright is only applicable on the container that is used for exchanging the data.
On the abstract concept of facts or data, copyright legislation does not apply.
The European directive on sui generis database law [8] specifies that, however, databases can be partially protected, if the owner can show that there has been qualitatively and/or quantitatively a substantial investment in either the obtaining, verification, or presentation of the content of the database
[9].
It allows a database owner to protect its database from (partial) replication by third parties.
So, while there is no copyright applicable on data itself, database rights may still be in place to protect a data source.
In 2014, the Creative Commons licenses were extended [10] to also contain legal text on the sui generis database law, and would since then also work for datasets.
More information on the definition of Open Data maintained by Open Knowledge International is available at opendefinition.org [11].
Data can only be called Open Data, when anyone is able to freely access, use, modify, and share for any purpose (subject, at most, to requirements that preserve provenance and openness)
.
Some data are by definition open, as there is no Intellectual Property Rights (ipr) applicable.
When there is some kind of ipr on the data, an open license is required.
This license must allow the right to reuse, modify, and share without exception.
From the moment there are custom restrictions (other than preserving provenance or openness), it cannot be called “open”.
While the examples given here may sound straightforward, these two ipr frameworks are the source of much uncertainty. Take for example the case of the Diary of Anne Frank [12], for which it is unclear who last wrote the book. While some argue it is in the public domain, the organization now holding the copyright states the father did editorial changes, and the father of Anne Frank died much later. For the reason of avoiding complexity when reusing documents – and not only for this reason – it is desired that the authoritative source can verify the document’s provenance or authors at all time, and a license or waiver are included in the dataset’s metadata.
When this book would be processed for the data facts that are stored within this book, what happens to copyright? Rulings in court help us to understand how this should be interpreted. A case in the online newspaper sector, Public Relations Consultants Association Ltd vs. The Newspaper Licensing Agency Ltd [13] in the UK in 2014, interpreted the 5th article of the European directive on copyright in the way that a copy that happens for the purpose of text and data mining is incidental, and no conscent should be granted for this type of copies.
Next, considering the database rights, it is unclear what a substantial investment is, regarding the data contained within these documents. One of the most prominent arrests for the area of Open (Transport) Data, was the ruling of the British Horseracing Board Ltd and Others vs. William Hill Organization Ltd [14], which stated that the results of horse races collected by a third party was not infringing the database rights of the horse race organizer. The horse race organizer does not invest in the database, as the results are a natural consequence of holding horse races. In the same way, we argue the railway schedules of a public transport agency are not protected by database law either, as a public transport agency does not have to invest in maintaining this dataset. These interpretations of copyright and sui generis are also confirmed by a study of the EU Commission on intellectual property rights for text mining and data analysis [9].
Sharing data: a challenge raising interoperability
A dataset is created in order for it to be shared at some point in time. If it is not shared with other people, it will need to be shared with other systems (such as an archive) or shared with your own organization. This is a use case we came across when visiting the Flemish Department of Transport and Public Works (dtpw), discussed in Chapter 4.2. Take for example a dataset that is created within a certain governmental service, for the specific use case of solving questions from members of parliament. While at first, the database’s design may not reflect a large number of use cases, the dataset is not just removed after answering this question. Instead, it will be kept on a hard drive at first, in order to be more efficient when a follow-up question would be asked. The dataset may also be relevant for answering different questions, and thus, a project is created to share this kind of documents proactively [15].
Imagine you are a database maintainer for this project, and someone asks to share the list of the latest additions with you. You set up a meeting and try to agree on terms regarding the legal conditions, you agree on how the data will be sent to the third party, discuss which syntax to use, the semantics of the terms that are going to be shared, and which questions that should be answered over the dataset. The protocol that is created can be documented, and whenever a new question needs to be answered, the existing protocol can be reused, or, when it would not cover all the needs any longer, needs to be rediscussed. When now more people want to reuse this data, it quickly becomes untenable to keep having meetings with all reusers. Also vice versa, when a reuser wants to reuse as much data as possible, it becomes untenable to have meetings with all data publishers.
In the previous chapter, we discussed datasets for which the goal was to maximize the reuse, which entails maximizing both the number of reusers, as well as maximizing the amount of questions each reuser can solve. In order to motivate data consumers to start reusing a certain dataset, some publishers rely on the intrinsic motivation of citizens [16], yet when performing a cost-benefit analysis, the cost to manually fix the heterogenity of datasets is still too high compared to the benefits of the company itself [17]. In this PhD, we explore the possibilities to lower this cost for adoption for a certain dataset, by lowering the data source interoperability [18], which we define as how easy it is to bring two, or more, datasets together.
Legally
The first level is the legal level: data consumers must be allowed for these two datasets to be queried together. When for a certain dataset a specific one on one contract needs to be signed before it can be used, the cost for adoption for data consumers becomes too high [17]. When two datasets are made available as Open Data and have an Open License attached to it, the interoperability problems will be lower. Even for datasets that are possibly in the public domain, the Open Data movement advocates for a clear disclaimer on each dataset with the publisher’s interpretation.
Technically
The second level is the technical level, which entails how easy it is to bring two datasets physically together. Thanks to the Internet, we can acknowledge this is possible today, yet the protocols to exchange data diverge, from e-mail, to the File Transfer Protocol (ftp), or the HyperText Transfer Protocol (http).
http [19], the protocol that powers the Web, allows actions to be performed on a given resource, called request methods or also called http verbs. It is up to the application’s developers to implement these methods. It is not uncommon that the “safe” property is not respected, resulting in undesired consequences in for example Mendeley back in 2012 [20]. The protocol defines for every method whether it is a safe method, defined as a method that does not change anything on the server.
An example of a safe method is get. By executing a get request, you can download the representation of a certain resource. The same representation can be requested over and over again with the same result, until the resource changes its state – e.g., when a train is delayed (a change in the real world), or when someone adds a comment to an article using a post request –. The result of this request can be cached within clients, in servers, or in intermediate caches.
post requests are not safe. Each time a post request is executed, a change or side-effect may happen on the server. It is thus not cacheable, as each new request must be able to trigger a new change or must be able to result in a different response.
The protocol has also more than a hand full of other methods, has headers to indicate specifics such as which encoding and format to use, how long the response can be cached, and has response codes to indicate whether the request was succesful. In this PhD, it is not up for debate whether or not to use http: the scale of adoption it has reached at the time of writing makes it the natural choice for the uniform interface. The rationale followed in this paper would also remain valid with other underlying protocols. In 2015, the http/2 protocol [21] was drafted and is today seeking for adoption. It is fully backwards compatible with http/1.1, the currently widely adopted specification.
Syntactically and semantically
The third kind of interoperability describes whether the serializations of both datasets can be read by a user agent. When deserialized, the data can be accessed in memory. The meaning behind these identifiers can conflict when the same identifier is used for something different. When they do not conflict, there may also be multiple identifiers for the same objects. In both ways, it will lower the semantic interoperability.
Interoperability layers
The term interoperability has been coined in several research papers, both qualitative as quantitative. What the authors of these papers have in common, is that they propose to structure interoperability problems in different categories. For example, back in 2000, the imi model [22] was introduced, in order to discuss the exchange of object oriented data between software systems. The imi model has only three levels: the syntax layer, the object layer and the semantic layer. The syntax layer is responsible for “dumbing down” object-oriented information into document instances and byte streams. The object layer’s goal is to offer applications an object-oriented view on the information that they operate upon. This layer defines how hierarchical elements are structured. Finally, the semantic layer is the layer that makes sure the same meaning is used for the same identifiers. The authors argue that each of these three layers should have their own technology to have a fully interoperable service. Today we indeed see that xml syntax has an object specification called rdf/xml, which standardizes how rdf triples can be contained within such a document.
Interoperability problems were also described as problems that occur while integrating data. The goal of an integration process is to provide users with a unified view on one machine. Four types of heterogeneity are discussed: Implementation heterogeneity occurs when different data sources run on different hardware and structural heterogeneity occurs when data sources have different data models, in the same way as the object level in the imi model. Syntax heterogeneity occurs when data sources have different languages and data representations. Finally, semantic heterogeneity occurs when “the conceptualisation of the different data sources is influenced by the designers’ view of the concepts and the context to be modelled”.
Legal, organizational, political, semantic, and technical are then again the five levels in which Europe categorizes their datasets on the European Union’s data portal in order to indicate for what interoperability level this dataset could be used. These levels are intended to discuss how data and knowledge is spread on a policy level within big organizations, such as Europe as a whole.
Finally, in a review on interoperability frameworks, four categories of interoperability are again identified: technical, syntactic, semantic and organizational. The first three are the same as in this paper, yet the organizational interoperability focuses on high level problems such as cultural differences and alignment with organizational processes. Within the data source interoperability, we consider the effects from organizational heterogeneity to have affected the semantic interoperability.
The 5 stars of Linked Data
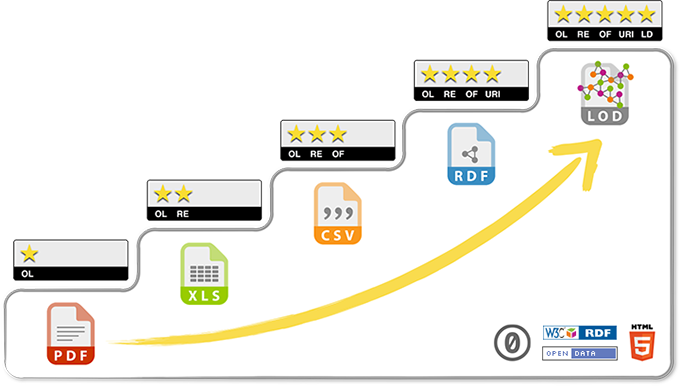
In order to persuade data managers to publish their data as “Linked Open Data”, Tim Berners-Lee introduced a 5 star rating for data in 2009, cfr. Figure 6. The first star advocates to make the data available on the web in whatever format, similar to our technical interoperability layer. This idea is also put forward by the World Wide Web Consortium (w3c) best practices guide for data on the Web [23] of the w3c. Furthermore, for open data, it also advocates for an Open License, similar to the legal interoperability layer. The second star requires that the dataset is machine readable. This way, the data that needs to be reused can be copy pasted into different tools, allowing for the data to be studied in different ways more easily. The third star advocates for an open format, similar to the syntactic interoperability, making sure anyone can read the data without having to install specific software. The fourth star advocates for the use of uris as a way to make your terms and identifiers work in a distributed setting, and thus allowing a discussion on semantics using the rdf technology. Finally, the fifth star advocates for reusing existing uri vocabularies, and to link your data to other datasets on the Web. Only by doing the latter, the Web of data will be woven together. The 5 star system to advocate for Linked Open Data has gained much traction and cannot lack from any introduction to Linked (Open) Data or maintaining datasets on web-scale. We however are cautious using the 5 stars in our own work, as it could give the impression a 100% interoperable 5 star dataset exists and no further investments would be needed at some point to make it better. For realists who rightfully believe a perfect dataset does not exist, wonder why going for 5 star data is needed… Are 3 stars not good enough? When presenting the roadmap as interoperability layers however, maintaining a dataset is a never ending effort, where each interoperability can be improved. Raising interoperability is not one-sided: the goal is to be as interoperable as possible with an information system. When the information management system, and the datasets in it do more effort towards interoperability, your dataset can also be made more interoperable over time.
Information management: a proposal
Let’s create a system to distribute data within our own organization for the many years to come. Our requirements would be that we want our data policy to scale: when more datasets are added, when more difficult questions need to be answered, when more questions are asked, or when more user agents come into action, we want our system to work in the same way. The system should also be able to evolve while maintaining backwards-compatibility, as our organization is going to change over time. Datasets that are published today, should still work when accessed when new personnel is in place. Such a system should also have a low entry-barrier, as it needs to be adopted by both developers of user agents as data publishers.
Tim Berners-Lee created his proposal for Information management on large scale within cern in 1989 [24]. What we now call “The Web” is a knowledge base with all of mankind’s data, which still uses the same building blocks as at the time of Tim Berners-Lee’s first experiments. For an overview of rest, we refer to the second chapter in the PhD dissertation of Ruben Verborgh, a review of rest after 15 years [25], or the original dissertation of Roy Fielding [26], or Fielding’s reflections about rest in 2017 [27]. It was Roy Fielding that, in 2000 – 11 years after the initial proposal for the Web –, derived a set of constraints [26] from what was already created. Defined while standardizing http/1.1, this set of “how to build large knowledge bases”-constraints is known today as Representational State Transfer (rest). As with any architectural style, developers can choose to follow these constraints, or to ignore them. When following these contraints, rest promises beneficial properties to your system, such as a good network efficiency, better scalability, higher reliability, a better user-perceived performance, and more simplicity.
Clients and servers implement the http protocol so that their communication is technically interoperable. Just like Linked Data insists on using http identifiers, rest’s uniform interface constraint requires that every individual information resource on the Web is accessed through a single identifier – a uri – regardless of the concrete format it is represented in. Through a process called content negotiation, a client and a server agree on the best representation. For example, when a resource “station of Schaerbeek” is identified by the uri http://irail.be/stations/NMBS/008811007 and a Web browser sends an http request with this uri, the server typically sends an html representation of this resource. In contrast, an automated route planning user agent will usually ask and receive a json representation of the same resource using the same uri. This makes the identifier http://irail.be/stations/NMBS/008811007 semantically interoperable, since clients consuming different formats can still refer to the same identifier. This identifier is also sustainable (i.e., semantically interoperable over time), because new representation formats can be supported in the future without a change of protocol or identifier [25].
In order to navigate from one representation to another, controls are given within each representation. Fielding called this Hypermedia As The Engine Of Application State (hateoas): when a user agent once received a start url, it would be able to answer its end-user’s questions by using the controls provided each step of the way.
Intelligent Agents
Now, we can create a user agent that provides its end-users with the nearest railway station. A user story would look like this: when you push a button, you should see the nearest station relative to your current location. In a Service Oriented Architecture (soa), or how we would naturally design such an interaction in small-scale set-ups, we expose a functionality on the server, which requires the application to send its current location to the server. A url of such a request would look like this: http://{my-service}/nearestStation?longitude=3.14159&latitude=51.315. The server then responds with a concise and precise answer. This minimizes the data that has to be exchanged when only one question is asked, as only one station needs to be transferred. Does this advantage weigh up to the disadvantages?
The number of information resources – or documents – that you potentially have to generate on the server, is over When assuming that a precision of 11m, or 4 decimal places in both longitude and latitude, is enough, then we would still have urls exposed for a simple feature. a trillion. As it is unlikely that two people – wanting to know the nearest railway station – are at exactly the same locations, each http request has to be sent to the server for evaluation. Rightfully, soa practitioners introduce rate limiting to this kind of requests to keep the number of requests low. An interesting business model is to sell people who need more requests, a higher rate limit. Yet, did we not want to maximize the reuse of our data, instead of limiting the number of requests possible?
Caching for scalability
As there are only 646 stations served by the Belgian railway company, describing this amount of stations easily fits into one information resource identified by one urlFor instance, https://api.irail.be/stations. When the server does not expose the functionality to filter the stations on the basis of geolocation, all user agents that want to solve any question based on the location of stations, have to fetch the same resource. This puts the server at ease, as it can prepare the right document once each time the stations’ list is updated. Despite the fact that now all 646 stations had to be transferred to the user agent, and thus consumed significantly more bandwidth, also this user agent can benefit. In Computer Science, this is also called the principle of locality For example, when soon after, a similar question is executed, the dataset will already be present in the client’s cache, and now, no data at all will need to be transferred. This raises the user-perceived performance of a user interface. When now the number of end-users increases by a factor of thousand per second – not uncommon on the Web –, it becomes easier for the server to keep delivering the same file for those user agents that do not have it in cache already. When it is not in cache of the user agent itself, it might already be in an intermediate cache on the Web, or in the server’s cache, not leading to the server having to invest in cpu time per user. We empirically study the effect of caching on route planning interfaces in Chapter 7. Caching, one of the rest constraints, thus has the potential to eliminate some network interactions and server load. When exploited, a better network efficiency, scalability, and user-perceived performance can be achieved.
See the Pen BQrJGv by Pieter Colpaert (@pietercolpaert) on CodePen.
The all knowing server and the user agent
In a closed environment – for instance, when you are creating a back-end for a specific app, you assume the information lives in a Closed World – a server is assumed to be all knowing. When asking for the nearest station, the server should know all stations in existence and return the closest one. Yet, when I would live nearby the border of France, a server that assumes a Belgian context will not be able to give me a correct answer to this question. Instead, I would have to find a different server that also provides an answer to this similar question. Furthermore, when now, I would love to find the nearest wheelchair accessible station, no answer can be returned, as the server does not expose this kind of functionality. The server keeps user agents “dumb”.
On the Web, we must take into account an Open World Assumption: one organization can only publish the stations it knows about, or a list of stations they use for their own use case. Not to mention that the complexities that would arise when datasets would not be interoperable. For instance, if not everyone had the same definition of “a station” An implication of this [28], is that for user agents, it becomes impossible to get the total number of stations: following links, they can infinitely keep crawling the Web whether there is someone that knows something about a station that was not mentioned before. However, a user agent can be intelligent enough, to, within its own context, decide whether or not the answers it received until now, are sufficient. For instance, when creating a public transport app in Belgium, the app can be given a complete list of transport agencies in Belgium, according to its developer. When a user agent is given a start url, it should be able to follow links to discover other information resources. When this user agent discovers and retrieves a list of stations published by all transport agencies, it can assume its list will be sufficient for its use case.
Queryability
For scalability and user-perceived performance, we argued that publishing information resources with fewer server-side functionality is a better way of publishing Open Data. We also argued that in the case of solving all questions on the server, the server pretends to be all knowing, when in fact it is not: it just has a closed world approach. The user agent has to adopt the specific context of the server, and is not able to answer questions over multiple servers at once. A user agent should be able to add its own knowledge to a problem, coming from other data sources on the Web or from the local context it currently has.
It is not because two datasets are legally, technically, syntactically, and semantically interoperable, that a user agent can answer questions over these two datasets without any problem. A query answering algorithm also needs to be able to access the right parts of the data at a certain moment. First, we can make the server expose over a trillion information resources of our data, by answering all specific questions on the server. However, as previously discussed, the questions that can be answered depend on the server infrastructure and the server context. Combining different services like this becomes increasingly difficult. This idea is taken from soa, and is not a great match for maximizing the reuse of open datasets.
Another option is that the data publisher publishes one data dump of all data within an organization. While this is preferred over a service when a diverse range of queries is needed, a data dump has clear drawbacks too. For instance, when the dataset would update, the entire dataset needs to be downloaded and reprocessed by all user agents again. Furthermore, for a user agent that only wants to know the nearest station, the overhead to download and interpret the entire file becomes too big. The possibility that data is downloaded that will never be used by the user agent becomes bigger too.
Instead of choosing between data dumps and query services, we propose to explore options in-between. Only one very simple question, asking for all data, can be answered by the server itself. It is up to the user agent to solve more specific questions locally. When the dataset is split in two fragments, e.g., all stations in the north of the country and all stations in the south of the country, the user agent can, depending on the question that needs to be solved, now choose to only download one part of the dataset. When publishing data in even smaller fragments, interlinked with each other, we help user agents to solve questions in a more timely fashion. The more fragments are published by the server, the more expressive we call a server interface. With this idea in mind, Linked Data Fragments (ldf) [29], illustrated in Figure 7, were introduced. Publishing data is making trade-offs: based on a publisher’s budget, a more or less expressive interface can be installed.
Just like a database that will be prepared to answer certain types of questions, a hypermedia interface can also be modeled for the questions it needs to answer. By providing extra controls and by providing more fragments of the data to be retrieved, the queryability of the interface will raise for particular problems.
Conclusion
The goal of an Open Data policy is to share data with anyone for any purpose. The intention is to maximize the reuse of a certain data source. When a data source needs to attract a wide variety of use cases, a cost-benefit analysis can be made: when the cost for adoptions is lower than the benefits to reuse this data, the data is going to be adopted by third parties. This cost for adoption can be lowered by making data sources more interoperable.

In order to make it more feasible for developers to make their app work globally instead of only for one system, we introduced the term data source interoperability. We define interoperability as how easy it is to evaluate questions over two data sources. The term can then be generalized by comparing your data source with all other data sources within your organization, or even more generally, all other data sources on the Web. We discussed – and will further study – interoperability on five levels, as illustrated in Figure 8:
- Are we legally allowed to merge two datasets?
- Are there technical difficulties to physically bring the datasets together?
- Can both syntaxes be read by the user agent?
- Do both datasets use a similar semantics for the same identifiers and domain models?
- How difficult is it to query both datasets at once?
We only consider data here that has to be maximally disseminated. On the legal level, public open data licenses help to get datasets adopted. It is not because the content of a license complies to the Open Definition, that the cost for adoption is minized. Licenses that are custom made may not be as easy to use, as it needs to be checked whether it indeed complies. On the technical level, we are still working on better infrastructure with http/2. On the syntactic level, we are working on efficient ways to serialize triples data facts in data [30], such as with the on-going standardizing work with JSON-LD, on-going research and development within for example hdt, csv on the Web, or rdf-thrift. On the semantic level, we are looking for new vocabularies to describe, avoid conflicts in identifiers using uris, and make sure our data terms are documented. And finally, when querying data, we are still working on researching how we can crawl the entire Web with an Open World assumption [28], or how to query the Web using more structured Linked Data Fragments interfaces.
In this chapter we did not mention data quality. One definition defines data quality as the perceived data quality when an end-user wants to use it for a certain use case. E.g., “The data quality is not good, as it does not provide me with the necessary precision or timeliness”. However, for other use cases the data may be perfectly suitable. Another definition mentions data quality as how close it corresponds to the real world. Furthermore, is it really a core task of the government to raise the quality of a dataset beyond the prime reason why the data was created in the first place? When talking about Open Data, the goal is to maximize data adoption by third parties. Even bad quality data – whatever that may be – might also be interesting to publish.
Interoperability is a challenge that is hard to advance on your own: also other datasets need to become interoperable with yours. It is an organizational problem that slowly finds its way into policy making. In the next chapter, we discuss how we can advance interoperability within large organizations.
References
- [1]
- Shafranovich, Y. (2005, October). Common Format and mime Type for csv Files. ietf.
- [2]
- Beckett, D., Berners-Lee, T., Prud’Hommeaux, E., Carothers, G. (2014, February). rdf 1.1 Turtle – Terse rdf Triple Language. w3c.
- [3]
- Carothers, G., Seaborne, A. (2014, February). rdf 1.1 N-Triples – A line-based syntax for an rdf graph. w3c.
- [4]
- Schreiber, G., Raimond, Y. (2014, February). rdf 1.1 Primer. w3c.
- [5]
- Berners-Lee, T., Fielding, R., Masinter, L. (2005, January). Uniform Resource Identifier (uri): Generic Syntax. ietf.
- [6]
- Vandenbussche, P.-Y. (2017). Linked Open Vocabularies (lov): a gateway to reusable semantic vocabularies on the Web. Semantic Web 8.3 (pp. 437–452).
- [7]
- European Parliament (2001). Directive 2001/29/EC of the European Parliament and of the Council of 22 May 2001 on the harmonisation of certain aspects of copyright and related rights in the information society. eur-lex.
- [8]
- European Parliament (1996). Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases. eur-lex.
- [9]
- Triaille, J-P., de Meeûs d’Argenteuil, J., de Francquen, A. (2014, March). Study on the legal framework of text and data mining.
- [10]
- Creative Commons (2013, December). Creative Commons 4.0/Sui generis database rights draft.
- [11]
- Open Knowledge International (2004). The Open Definition.
- [12]
- Moody, G. (2016, April). Copyright chaos: Why isn’t Anne Frank’s diary free now?. Ars Technica.
- [13]
- Judgment of the Court (Fourth Chamber) (2014, June). Public Relations Consultants Association Ltd v Newspaper Licensing Agency Ltd and Others.. eur-lex.
- [14]
- Judgment of the Court (Grand Chamber) (2004, November). The British Horseracing Board Ltd and Others v William Hill Organization Ltd.. eur-lex.
- [15]
- Research Service of the Flemish Government (). Overview of datasets of the Flemish Regional Indicators.
- [16]
- Baccarne, B., Mechant, P., Schuurman, D., Colpaert, P., De Marez, L. (2014). Urban socio-technical innovations with and by citizens. (pp. 143–156). Interdisciplinary Studies Journal.
- [17]
- Walravens, N., Van Compernolle, M., Colpaert, P., Mechant, P., Ballon, P., Mannens, E. (2016). Open Government Data’: based Business Models: a market consultation on the relationship with government in the case of mobility and route-planning applications. In proceedings of 13th International Joint Conference on e-Business and Telecommunications (pp. 64–71).
- [19]
- Fielding, R., Gettys, J., Mogul, J., Frystyk, H., Masinter, L., Leach, P., Bernsers-Lee, T. (1999, June). Hypertext Transfer Protocol – HTTP/1.1. ietf.
- [20]
- Verborgh, R. (2012, July). get doesn’t change the world.
- [21]
- Belshe, M., Peon, R., Thomson, M. (2015, May). Hypertext Transfer Protocol Version 2 (http/2). ietf.
- [22]
- Melnik, S., Decker, S. (2000, September). A Layered Approach to Information Modeling and Interoperability on the Web. In proceedings of the ECDL’00 Workshop on the Semantic Web.
- [23]
- Farias Lóscio, B., Burle, C., Calegari, N. (2016, August). Data on the Web Best Practices.
- [24]
- Berners-Lee, T. (1989, March). Information Management: A Proposal.
- [25]
- Verborgh, R., van Hooland, S., Cope, A.S., Chan, S., Mannens, E., Van de Walle, R. (2015). The Fallacy of the Multi-API Culture: Conceptual and Practical Benefits of Representational State Transfer (rest). Journal of Documentation (pp. 233–252).
- [26]
- Fielding, R. (2000). Architectural Styles and the Design of Network-based Software Architectures. University of California, Irvine.
- [27]
- Fielding, R. T., Taylor, R. N., Erenkrantz, J., Gorlick, M. M., Whitehead E. J., Khare, R., Oreizy, R. (2017). Reflections on the REST Architectural Style and “Principled Design of the Modern Web Architecture”. Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (pp. 4–11).
- [28]
- Hartig, O., Bizer, C., Freytag, J.C. (2009). Executing sparql queries over the Web of Linked Data. In proceedings of International Semantic Web Conference. Springer Berlin Heidelberg.
- [29]
- Verborgh, R., Vander Sande, M., Hartig, O., Van Herwegen, J., De Vocht, L., De Meester, B., Haesendonck, G., Colpaert, P. (2016, March). Triple Pattern Fragments: a Low-cost Knowledge Graph Interface for the Web. Journal of Web Semantics.